
Can AI Agents Access, Crawl, and Render Your Site Pages?
AI crawlers need a little more help than search crawlers to access your site and find answers the need

Now that various AI platforms (like ChatGPT, Perplexity, Claude, etc.) run live searches more often to respond to prompts, it is important to make sure your site is crawlable by AI agents.
This will greatly improve your chances of getting cited in AI answers as well as help you control the narrative (get your product or brand mentioned).
>>>>HUGE ANNOUNCEMENT: I am starting A NEW subreddit focusing on all things AI analytics (measuring, tracking, testing, etc.). Please JOIN: /r/AISearchAnalytics/
1. Make sure your pages are readable with JavaScript disabled
Unlike Google crawlers, AI bots are still very immature. As many tests have shown (including the most recent one), all AI crawlers cannot render JavaScript.
Since Google has been able to render JavaScript for years now, publishers and businesses have stopped taking steps to ensure their websites are usable without it. As a result, there are a huge number of websites that use JavaScript heavily.
AI platforms don’t keep an index of visited pages or keep a cache of web pages. They need to “visit” your page every time they find it doing an external search (through Google, Bing, or other undisclosed sources) to “read” it and locate the information they need.
Most AI crawlers cannot render JavaScript, and even those that can may give up on trying if it takes time. Hence, ensuring all the important information is available without having to render JavaScript is very important.
Rendering Difference Engine is a free extension that clearly shows you which elements of your page may be invisible to crawlers that are unable to render JavaScript. Just install the extension, go to the page you want to analyze, and click the extension icon to load the analysis. The extension will load a separate window highlighting:
Headings that are hidden behind JavaScript elements (tabs or toggles) and are not readable
Invisible or unclickable links
Text that will not be readable because it needs JavaScript to be rendered to be visible
For example, this report shows that, out of 14 H6 headings, only 8 will be likely visible to AI crawlers:
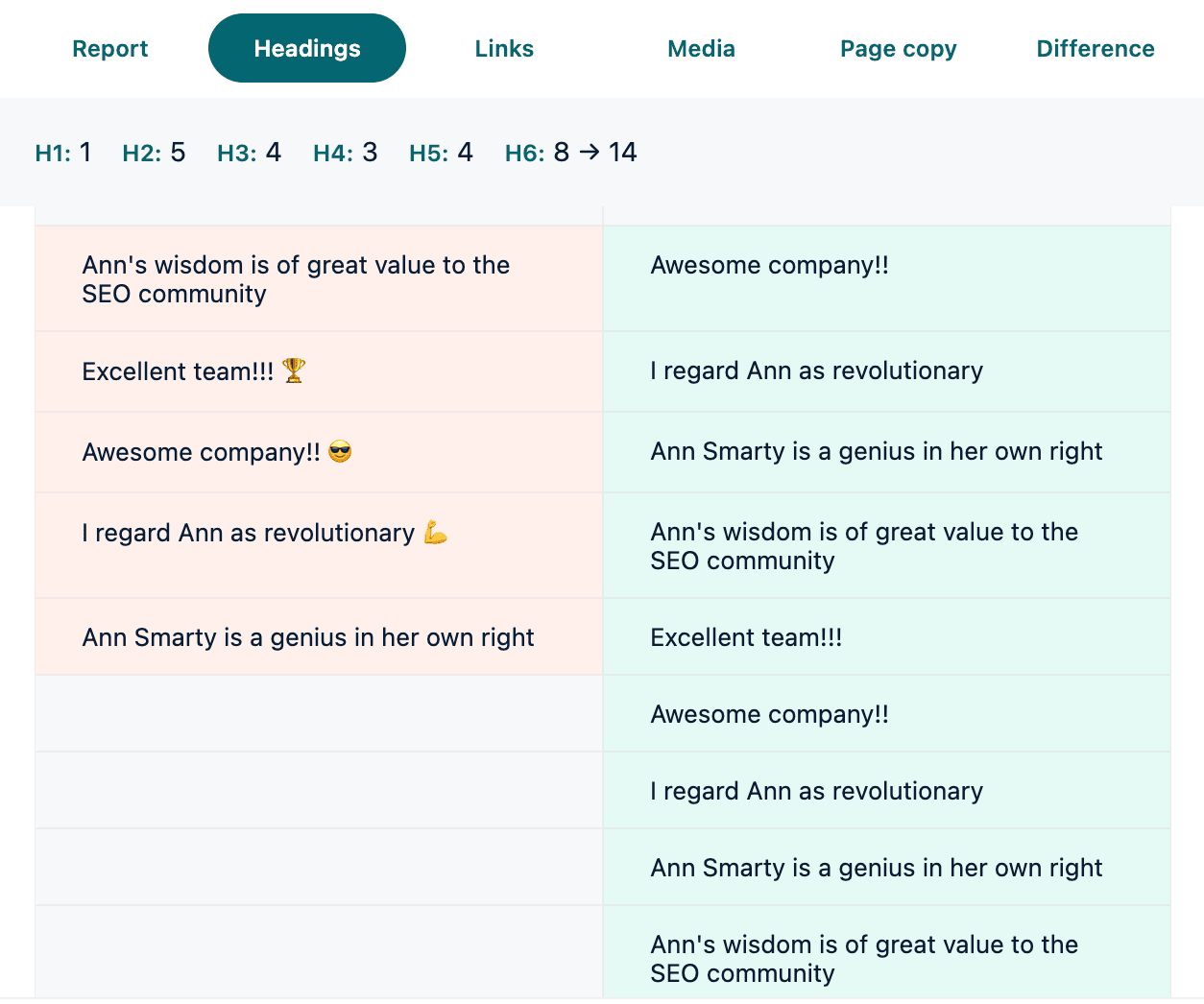
You can also highlight links on the page that can be followed by AI crawlers.
It is an easy way if all the important page elements are available for AI crawlers to see, fetch, and follow.
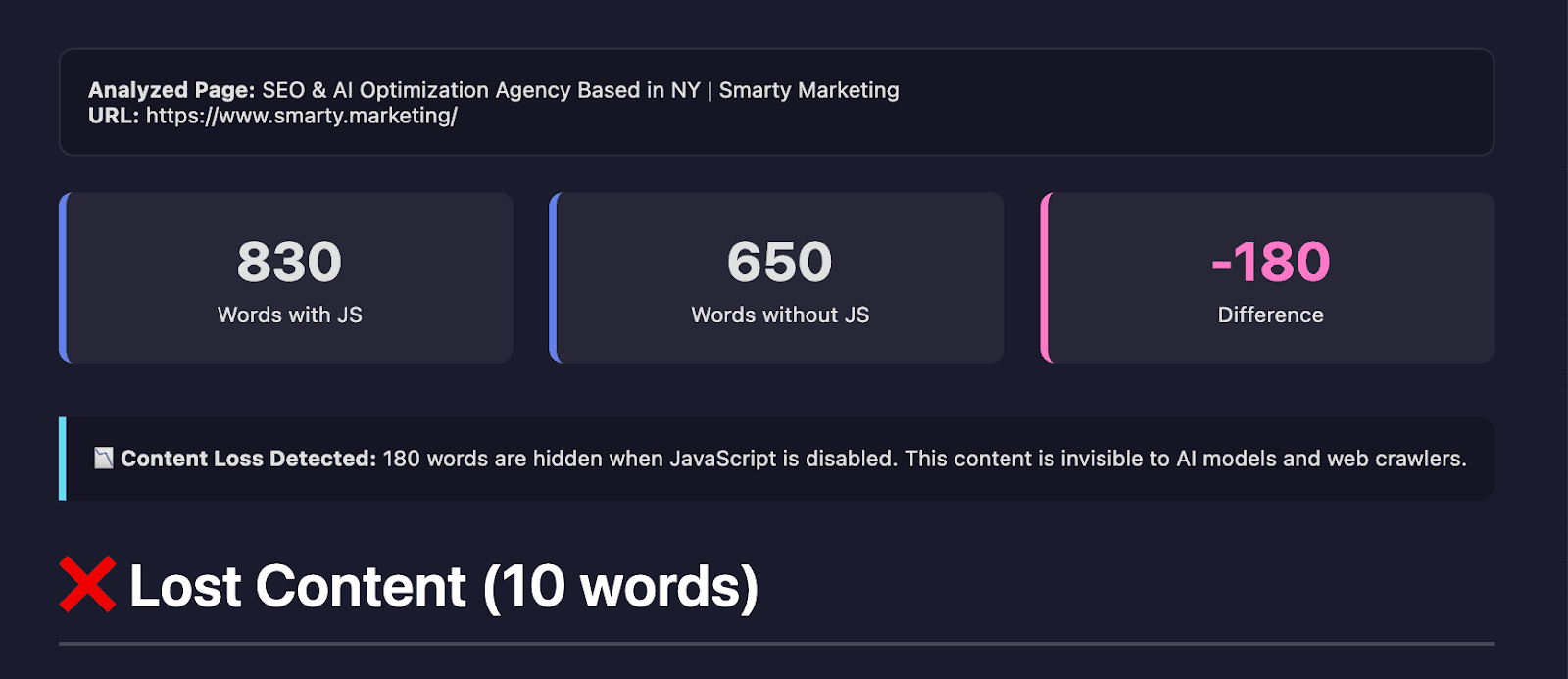
AI Words is another extension that “lets you see your page as AI sees it”. It focuses on text content. Once you load the page and click it, the extension will let you generate a report that will show you how much content is lost when JavaScript is enabled on your page. As you scroll down, you will see the words that may not be fetched by AI Crawlers
2. LLM models can access your page in different ways
We know that different models and even different modes from the same LLM model can access the page differently.
For example, Google’s LLM models are all different:
✅ Gemini App gets the page content in real time (you can see it in the logs).
❌ Gemini via API says it cannot access it.
❌ AI Mode lies about accessing the page and then hallucinates
(This often happened with ChatGPT previously, not yet sure if it has changed in GPT-5. Previously, ChatGPT would rather read the search snippet of a URL instead of going to the page directly).
So to make sure your page is readable by LLM:
Make sure it is indexed in Google and Bing
Keep an eye on your server logs for direct visits
3. Schema? Why NOT!
Oh the never-ending debate! Does structured markup help?

I’ve heard of personal tests saying it definitely does. There are many experts saying it makes no difference. There are lots of variables here that we cannot test:
No insight into actual training data
No consistency as to HOW AI agents may access your page:
Here’s a good explanation by Andrea Volpini:
structured data visibility varies dramatically between different LLM tool types.
When an AI agent uses a search tool (like GPT-5’s web.search or Gemini’s google_search and groundingMetadata), it gains full access to your structured data because search engines pre-index JSON-LD, microdata, and RDFa markup. The agent receives rich, semantically-enhanced snippets with complete entity information.
However, when an agent uses direct page access tools (like open_page or browse), a critical gap emerges: JSON-LD structured data becomes largely invisible. Only microdata embedded directly in HTML attributes remains accessible to the agent during direct page parsing.
The bottom line here: If there’s a small chance schema can help, let’s use it. It won’t hurt, and it takes seconds to implement. We also have a variety of free generators if you need them:
In case you need help, I am one email or one call away!