
How Are AI Answers Created (And What/How Are We Optimizing for)
Everyone is obsessed with AI visibility optimization (GEO / AEO), so here are the clear steps on what it takes!

For about three years now, everyone has been arguing about optimizing for AI visibility, i.e., being present in AI answers (and being cited as a source there).
But do we actually know how AI answers are created?
There are many steps there, and we don’t have much insight into most of them.
But first two announcements:
👉 JOIN us to discuss this topic LIVE (free, no registration required!)
👉 Ask your questions in your week’s AMA on Reddit! This week, the awesome Cyrus Shepard is hosting an AMA on AI, SEO, EEAT and more!
Here’s how AI answers are generated, in a very simplified way:
1️⃣ Training-layer: In many cases, an LLM won’t even go further. It already confidently knows the answer. There are no URLs at this point. Training data doesn’t store links from where it found the answer. If there are citations for these answers, they will be reverse (citing pages that support a pre-written answer)
2️⃣ Retrieval-eligibility: When an LLM decides to search, if your page is found for one of the fan-out queries (which are also largely determined by training data: Which brands it knows to search for, which publications it knows will likely give trusted answers, etc.). Where it is searching is unconfirmed, but mostly Google for now (and likely some partnerships, etc.).
3️⃣ Retrieval-ranking: It finds URLs, now it chooses which ones to “read”. Correct me if I am wrong, but we really don’t have much insight into how it makes a selection.
4️⃣ Extraction: Which content ends up being pulled into the answer? This is where content clarity, structure, etc., likely comes into play.
5️⃣ Citation-slot assignment: So an LLM picked URLs, pulled an answer, etc. Now it chooses what to cite. This is where it gets interesting. It can cite URLs it “read” and pulled answers from (4️⃣), it can cite URLs it never read but retrieved (3️⃣), or it can pull random URLs that never came up in 2-3-4 (from partners, or even hallucinate them). AND YET, this is pretty much all we can see/measure/test. The gap of how URLs got here is huge (see above).
As an industry, we overfocus on and measure 5️⃣, we optimize for 4️⃣, and tend to ignore 1️⃣ (which determines everything).
Let’s put it altogether:
1. Training layer
It is not SEO.
It’s all about building a known brand with a clear value proposition that answers a question or solves a problem in a prompt.
2. Retrieval-eligibility
This step is purely SEO: If your URLs rank well for what an LLM is searching for, it will be found by an LLM.
3. Retrieval-ranking
This is kind of SEO too, even though we really don’t know how LLMs pick which retrieved URL to “read”. It likely depends on:
Rankings (the closer to the top your URL is ranking, the better the chances are LLMs will visit it to find answers)
Search snippets (if the search snippet looks very relevant to the question behind the prompt, it will likely be picked for answer extraction). This is where schema may help a lot!!!
4. Extraction
This is kind of SEO too, or Answer Engine Optimization (if you need a new acronym to impress your boss).
5. Citation-slot assignment
This is what SEOs tend to stress about even though there is 0 clarity as to what will ultimately get cited.
Actual URLs that were found and pulled answers from may never get cited.
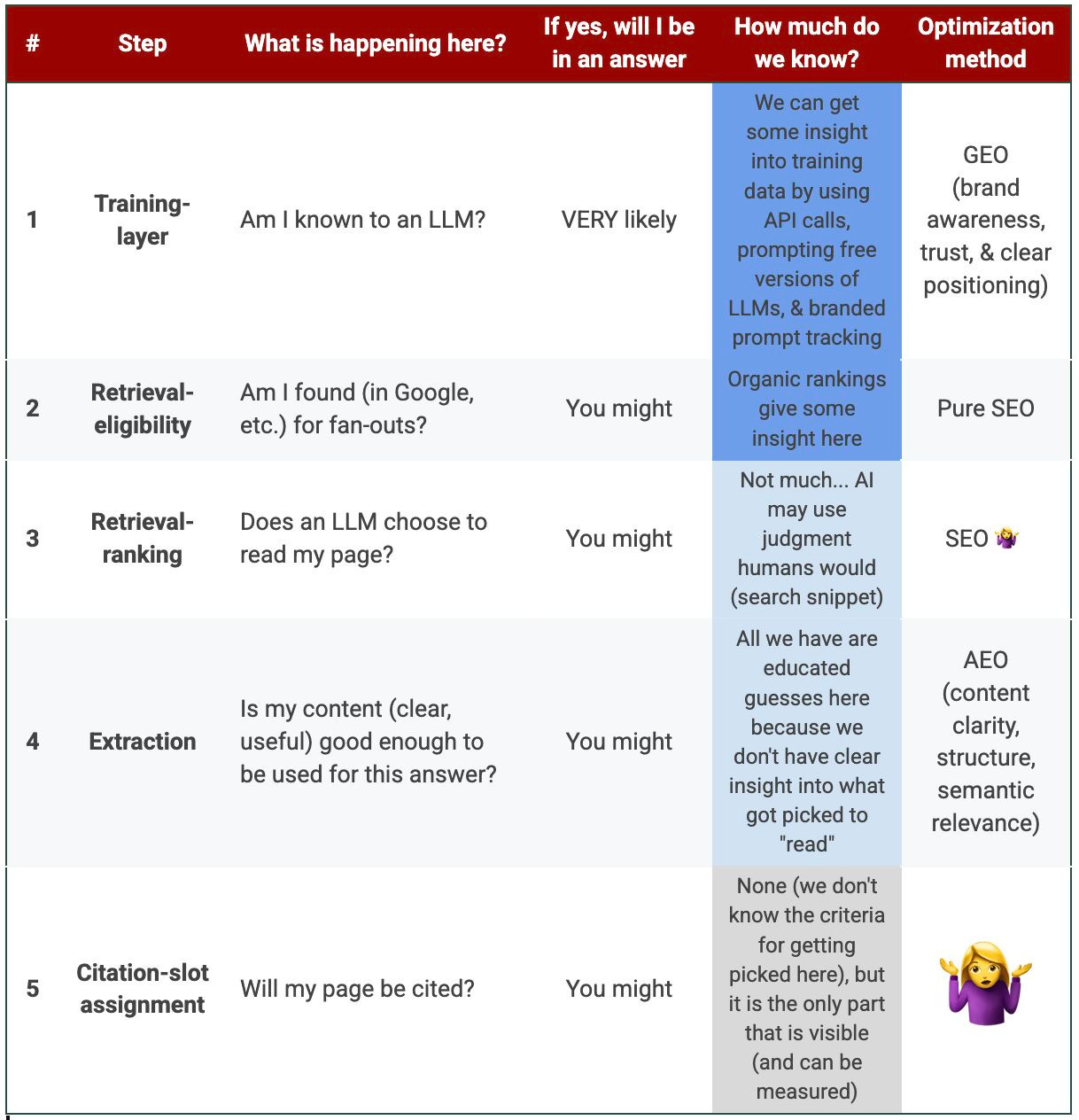
I like how clearly this breaks down the AI answer process.
What stands out is that everyone is obsessing over citations, but they are almost the final layer. By the time a source is cited, a lot has already happened.
The model has already decided whether it needs retrieval.
It has already generated fan-out queries, a set of pages, and extracted information.
Only after all of that does the citation decision happen.
This is why chasing citations alone feels incomplete. A brand can be part of the answer and still not be cited, or it may never even enter the retrieval layer because it is not clear enough, crawlable enough, or strongly associated with the topic in the first place.
The real work is not just citation tracking. It is building a brand and content system that AI can discover, understand, extract from, and confidently attribute.
That is where FTA Global’s Search Engineering becomes important. It sits between SEO, content clarity, technical access, brand signals, and off-site proof.
very good!